I’ll avoid the predictable setup statements here (e.g. Analyst ABC predicts that blah blah blah) and just jump right in on our topic: containers and microservices. If you’re anything like me (not a software developer), you’ve probably heard these terms and maybe have a fuzzy sense of their meaning and the benefits they offer, but the details elude you. If so, this article series is for you.
One quick word about why this matters. Software architectures are like building foundations. You never think twice about good ones, but you’ll definitely notice (and pay for) bad ones. And, it’s difficult to change the foundation once the structure is built. There’s this general sentiment in the networking industry that software problems (unreliable code releases, buggy products, and slow velocity) are the fault of “bad QA,” but the reality is that QA organizations face an impossible task because the product architecture itself leads to these problematic software artifacts.
Good architectures enable continuous integration and continuous deployment (CI/CD) with automated QA, which enables scalability, reliability, and velocity at the same time. Containers and microservices change the game for software foundations. We can keep talking benefits, but it might help to explain how the technologies work and why they drive those benefits.
Containers
Containers are lightweight, standalone executable software packages that include everything needed to run: code, system tools, libraries, frameworks, and settings.
If you’re not a developer, that definition may not make sense to you, but stick with me. Containers are simply a way to bundle together some code and all of its operating dependencies such that the package is all-inclusive. By packaging it up as a bundle, it becomes self-contained and can be run reliably in any container environment, which makes it more predictable and easier to maintain and operate.
The problem being solved by containers is not very obvious when you think about version 1.0 of an application. The 1.0 release has clean software and works just fine. Then new features are added over time, existing features are modified, and they share underlying code and components. The environment keeps evolving to fit new requirements while maintaining backward compatibility, but the interoperation matrix grows exponentially with added features, underlying software components and versioning, and dependencies (FeatureA needs ComponentY to be on VersionN, FeatureB needs ComponentY to be on VersionQ, etc). This is exactly what happens with traditional networking software, which is why QA teams have issues keeping up. Containers solve this complexity problem for developers and QA. But how do they really work?
Containers are commonly compared to virtual machines because their function is roughly similar—to run multiple isolated workloads on shared HW resources. You can think of containers a bit like lightweight VMs. As illustrated in the image below, virtual machines deliver workload sharing by virtualizing hardware (via the hypervisor) and then running multiple guest OSes on top. Container systems “virtualize” the host OS itself so that workloads can be run within containers without requiring a full guest OS. In other words, it provides a more direct route to the host’s processes and subsystems without requiring all the overhead of another OS.
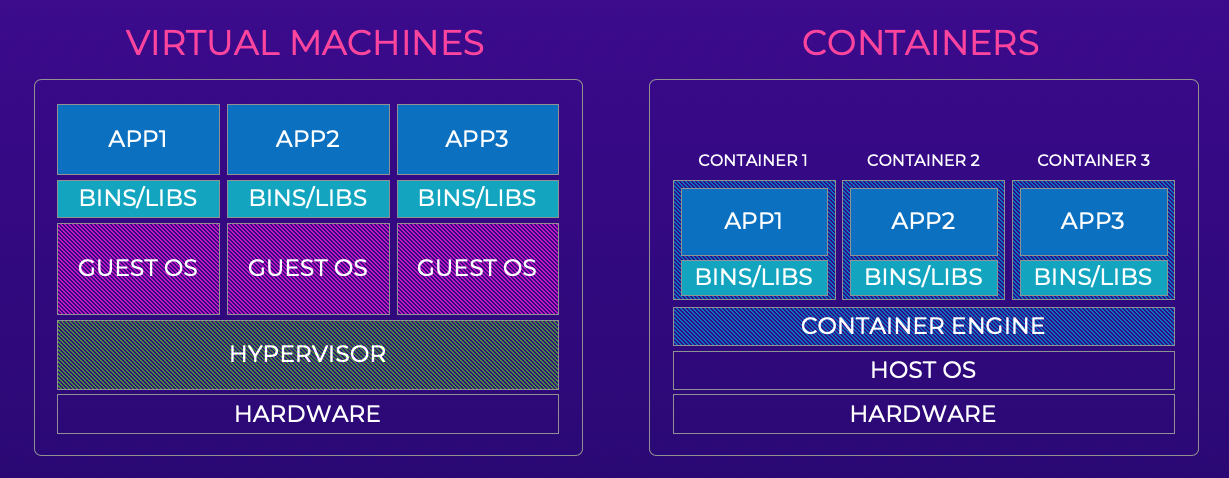
Compared to other software design options, containers provide several benefits.
Lightweight
Containers reduce the resource footprint by running directly on the host’s kernel without requiring a guest OS, which takes up CPU, memory, and disk. This makes them much more efficient than VMs, reduces the hardware resources required to run the app, and saves cost.
Predictable
By packaging an app with all of its dependencies, containers are extremely predictable and portable because they work the same way in any container environment. This allows for better operating consistency in production environments (i.e. customer networks) because the same container code is running in development, QA, and production environments, and you’re never missing a minor dependency that causes quality issues.
Isolated
Containers also keep software cleaner over time because it allows the development team to isolate and decouple services from one another and avoid unnecessary reuse of dependency components, libraries, or other code. This bypasses that issue where FeatureA and FeatureB have conflicting dependencies, because we just run FeatureA and FeatureB as separate containers and update their dependencies independently.
Agile
By sandboxing code into well-defined units, software teams gain development, maintenance, and testing efficiencies. Developers can add containers or modify existing containers without impacting other containers that are isolated.
Fast and Scalable
In a production application with dynamic real-time requirements, containers start up very quickly and do not rely on an underlying VM to boot. Once started, they can also be scaled up or down independently from other services in other containers. This is also managed with orchestration tools like Kubernetes (K8s), or hosted Kubernetes solutions like AWS’s EKS.
Containers and Microservices
Containers are just a part of the architectural design equation. To be honest, you could take a giant monolithic application and just run it as a single monster container (like a VM), but that doesn’t really help us in any way. When we combine containers into a microservices architecture, then we see the full value. We’ll jump into microservices in our next article and bring it all together.
For more reading and resources about containers, try these. Sometimes hearing the same thing in different ways will turn the lightbulb on:
For more information about Extreme’s intelligent and modern public, private, and local cloud options, here’s a link to our wares: https://extremeengldev.wpengine.com/latam/products/.
This blog was originally authored by Marcus Burton, Architect, Cloud Technology
 Regístrate ahora
Regístrate ahora

